Интеграция Azure Synapse с ClickHouse
Azure Synapse — это интегрированный аналитический сервис, который объединяет большие данные, data science и хранилища данных, позволяя быстро анализировать большие объемы данных. В Synapse пулы Spark предоставляют масштабируемые по требованию кластеры Apache Spark, которые позволяют выполнять сложные преобразования данных, машинное обучение и интеграцию с внешними системами.
В этой статье показано, как интегрировать коннектор ClickHouse Spark при работе с Apache Spark в Azure Synapse.
Добавьте зависимости коннектора
Azure Synapse поддерживает три уровня управления пакетами:
- Пакеты по умолчанию
- Уровень пула Spark
- Уровень сеанса
Следуйте руководству Manage libraries for Apache Spark pools и добавьте в приложение Spark следующие обязательные зависимости:
clickhouse-spark-runtime-{spark_version}_{scala_version}-{connector_version}.jar— официальный Mavenclickhouse-jdbc-{java_client_version}-all.jar— официальный Maven
Ознакомьтесь с документацией Spark Connector Compatibility Matrix, чтобы определить, какие версии подходят для ваших задач.
Добавьте ClickHouse как каталог
Есть несколько способов добавить конфигурации Spark в ваш сеанс:
- Пользовательский файл конфигурации, загружаемый вместе с сеансом
- Добавьте конфигурации через интерфейс Azure Synapse
- Добавьте конфигурации в ноутбуке Synapse
Следуйте инструкции Управление конфигурацией Apache Spark и добавьте конфигурации Spark, необходимые для коннектора.
Например, вы можете настроить сеанс Spark в ноутбуке, указав следующие параметры:
Убедитесь, что в первой ячейке указано следующее:
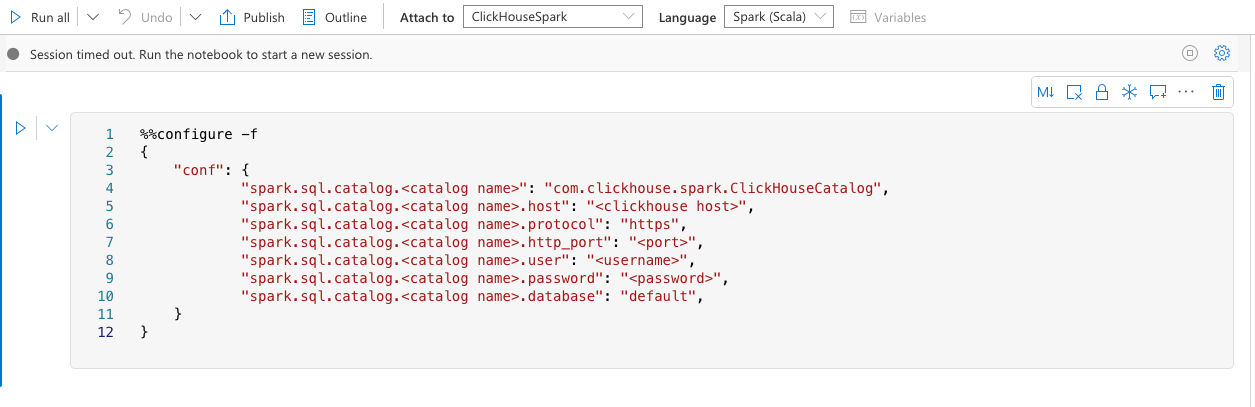
Дополнительные параметры см. на странице конфигураций ClickHouse Spark.
При работе с ClickHouse Cloud обязательно задайте необходимые параметры Spark.
Проверка настройки
Чтобы убедиться, что зависимости и параметры конфигурации заданы успешно, откройте Spark UI для вашего сеанса и перейдите на вкладку Environment.
Там найдите настройки, связанные с ClickHouse:

